



The rise and fall of ModSecurity and the OWASP Core Rule Set (thanks, respectively, to robust and adversarial machine learning)
Adversarial ModSecurity: Countering Adversarial SQL Injections with Robust Machine Learning

Following last week's post where we talked about the performance evaluation of AppSec and Cybersecurity tools,

we will now move to the practical evaluation of two outstanding projects ModSecurity and the OWASP Core Rule Set.
I’m really glad to write this post since the contents are the outcome of an original research work jointly carried out by our team in Pluribus One (the company which I co-founded and of which I’m the CEO), together with the Application Security research teams in SAP and EURECOM @Sophia Antipolis (btw: if you are curious about what we do in Pluribus One check our flagship product website). Incidentally, the work was carried out in the context of the research project TESTABLE, funded by the European Commission which aims to overcome the limitations we currently face while testing Web Applications for security issues. Web Application Firewalls are of course within the perimeter of such verifications and so here we are with the research work and this article.
In the research work, we show that the detection strategy implemented by ModSecurity, which relies on assigning weights to a set of static rules and calculating if the sum of the weights corresponding to the rules activated by a single request exceeds a given threshold, is largely ineffective for detecting SQL injection (SQLi) attacks, as it tends to block many legitimate requests, while also being vulnerable to adversarial SQLi attacks, i.e., attacks intentionally manipulated to evade detection.
The research work provides a thorough evaluation of the ModSecurity performances, and proposes two strategies to:
help find a better tradeoff between false positives and detection rate and
make it more robust against adversarial attacks. Both strategies leverage (robust) Machine learning to achieve the goal.
Before entering into details of the work, here is how this post will be organized:
I will describe what ModSecurity and the Core Rule Set are and the basic principles of their functioning;
I will describe why the way they work isn't optimal for finding a good balance between false positives and true positive rates (or detection rate if you prefer this name) and why it makes them vulnerable to adversarial attacks;
we will enter into details of their performances and compare the vanilla ModSecurity performances with the modified model we have proposed.
About ModSecurity and the OWASP Core Rule Set
ModSecurity, often referred to as ModSec, is a widely used open-source web application firewall (WAF). Initially developed by Ivan Ristić in the early 2000s, it has become a standard tool in the arsenal of many system administrators and webmasters. Its flexibility and power come from a rule-based language that can inspect HTTP traffic and make decisions on whether to allow, block, or redirect requests based on their content. ModSecurity operates using a set of rules that define malicious behavior. These rules can detect SQL injection, cross-site scripting (XSS), local and remote file inclusion, and many other types of attacks. While ModSecurity itself is the engine that processes rules and acts based on them, the actual rules that define malicious behavior come from the OWASP Core Rule Set (CRS).
The CRS provides a set of generic rules that offer protection against a wide variety of common web application attacks. Administrators can use the CRS as a starting point and then customize or extend it to fit their specific needs. The Core Rule Set (CRS) initiative by the Open Web Application Security Project (OWASP) stands as one of the premier open-source collections of rules designed to detect web-based threats, particularly focusing on the OWASP Top 10 security vulnerabilities. Notably, this rule set serves as the benchmark for various open-source Web Application Firewall (WAF) platforms, including renowned ones like ModSecurity and Coraza, which are typically deployed as a module for popular web servers and reverse proxies like Apache, Nginx, IIS, or HAProxy. Once installed and configured, they act as a protective barrier between the web application and potential attackers, examining HTTP requests and deciding on their legitimacy based on their rule set. Additionally, over a dozen commercial solutions, encompassing giants like Google Cloud Armor, Microsoft Azure, Amazon Web Services (AWS), and Cloudflare WAFs, have integrated the CRS into their systems.
As for the specifics of the Detection Rules within CRS, they predominantly employ regular expressions (regex) for implementation. To illustrate, the regular expression, which is the sequence following @rx on the first line in Figure 1, identifies multiple SQLi attack comment patterns, including sequences like ";--" and "-- ". Each rule also bears a distinct identifier, as seen with 'id' on

the second line; for instance, the rule in the example is marked as 942440. Furthermore, this identification system also categorizes the type of attack. For example, rules beginning with 942 are specifically tailored to detect SQLi attacks. Rounding off the attributes present in the figure, two significant ones include the Paranoia Level (highlighted on line #7) and the severity level (noted on line #9). Both are integral to CRS's unique anomaly scoring strategy. Both are described in the following.
Paranoia Level. The Paranoia Level (PL) functions as a configuration setting that determines the active rules for inspecting HTTP requests. Within CRS, there are four defined PLs, ranging from PL1 to PL4, with each rule being allocated to a particular PL. For instance, the rule shown in the figure falls under PL2, as indicated on line #7. Importantly, rules are hierarchically organized by their PL: activating a given PL will not only enable the rules specific to that level but also those of the preceding levels. For example, selecting PL3 will activate its designated rules and also those under PL1 and PL2. Naturally, selecting PL4 activates the entirety of the rule set.

It's noteworthy that SQLi vulnerabilities have been given significant emphasis within CRS. Out of a total of 249 rules, 49 are dedicated to addressing SQLi. Breaking it down further by PL (refer to the outer circle of Figure 2), PL1 contains 16 rules (representing 33%), PL2 has 24 rules (accounting for 49%), PL3 encompasses 7 rules (or 14%), and PL4 includes 2 rules, which is 4% of the SQLi-focused rules.
Anomaly Scoring. Every detection rule is ascribed to a severity level based on heuristic principles, represented as a positive integer. This integer gauges the potential threat level of detected requests. In its decision-making process, ModSecurity evaluates incoming requests against these rules, tallying up the severity levels for all matching instances. If this cumulative score surpasses a predefined limit, the request is labeled as malicious. Within CRS, severity levels are categorized into four tiers: CRITICAL (5), ERROR (4), WARNING (3), and NOTICE (2). To illustrate, the rule displayed in the figure above 3 is assigned a CRITICAL severity (as seen on line #9), implying its contribution to the overall anomaly score is 5 (referenced on line #10). When examining the weight distribution of SQLi rules (refer to Figure 2), a significant 42 rules (or 86%) are classified with a severity of 5 (CRITICAL). In contrast, the remaining 7 rules (equivalent to 14%) carry a weight of 3 (WARNING).
Where the problems stand
Even if the severity level of the detection rules is assigned by domain experts, such a process remains purely heuristic. This strategy tends indeed to produce a largely sub-optimal trade-off between the detection rate and the false alarm rate exhibited by the ModSecurity WAF. This is primarily because its weighting system is rooted in heuristics that focus solely on attack patterns, overlooking the characteristics of genuine incoming traffic aimed at the safeguarded services. This is the first main shortcoming identified in the research work. Secondly, our findings reveal a pronounced susceptibility in ModSecurity to adversarial SQLi attacks. These involve slight alterations to harmful SQLi samples, allowing them to bypass detection while preserving their malicious capabilities. To delve deeper into this vulnerability, we employ a renowned black-box fuzzer called WAF-A-MoLE to fine-tune these adversarial SQLi attacks against ModSecurity. Our experiments draw from an extensive public dataset, comprising over 700,000 legitimate and malevolent samples.
How can the problem be solved?
To address the two problems above, the research work proposes two different approaches:
one, named MLModSec, leverages ML to identify an optimal combination of CRS rules and thus to identify an optimal tradeoff between True Positive and False Positive rates;
the second, named AdvModSec, adds Adversarial training to the model to make it capable of withstanding evasion attacks. This technique integrates the computation of adversarial examples at training time, thus giving the model the possibility of knowing in advance evasive patterns that could be computed at test time and making the model robust against input changes.
In both cases, the key idea is to build a feature space using the CRS rules and develop machine-learning models in this space. The two steps required to implement both solutions are:
A feature extraction step that translates the CRS rules activated by the input samples (e.g., SQL queries) into a vector format.
A machine-learning step model that determines the optimal way to merge the CRS rules to reduce classification mistakes. We tested with two widely used approaches, like Support Vector Machines and Random Forests.
Regarding the feature extraction step, we can think of detection rules as Features. The data we're working with consists of SQL queries that a machine-learning tool needs to categorize as either harmful or safe. Each SQL query is matched against all the detection rules in the set. If a specific rule from our list applies to the SQL query, we put a 1 in our list. If not, we put a 0. This way, we get a unique list of 0s and 1s for every SQL query, helping us understand which rules apply to it. Thus, each query is represented by a feature vector which is in essence a sequence of 1s and 0s corresponding respectively to the rules that have respectively matched and not matched as long as the number of rules in the set.
Finally, here is a review of the data used to run the test. The work starts from the WAF-A-MOLE dataset, which contains 393,629 malicious and 345,199 benign SQL queries. While it may not mimic real-world scenarios, it's currently the most extensive dataset for SQLi detection training. Benign samples derive from a restricted SQL grammar, while malicious samples are generated using tools like Sqlmap and OWASP ZAP. The following four sub-datasets have been built out of it:
Training set (train): 20,000 samples, evenly split between benign and malicious SQL queries, randomly selected from the main dataset.
Test set (test): 4,000 random samples (2,000 benign and 2,000 malicious), distinct from the training set. It evaluates the performance of various Web Application Firewalls (WAFs), including vanilla ModSecurity, MLModSec, and AdvModSec.
Adversarial training set: Consists of 5,000 malicious queries from the training set, altered using WAF-a-MoLE, and then added back to the main training set for adversarial training.
Adversarial test set (test-adv): Created by optimizing the malicious queries in the test set with WAF-a-MoLE, while benign samples remain unchanged. It assesses the WAFs' resistance to adversarial attacks.
For each of the four possible paranoia levels, the performance of the SVM and RF classifiers was calibrated using the CRS rules and gauged against two distinct datasets: the regular test set (test) and its adversarial counterpart (test-adv).
Vanilla ModSecurity: not that good.
The primary aim of the empirical study is to gauge the predictive prowess of the stock ModSecurity when utilizing CRS. Instead of merely relying on its out-of-the-box settings, tests across its full spectrum of configurations have been conducted. This encompasses the four distinct Paranoia Levels (PLs) and the customizable classification threshold available in ModSecurity. For every PL, we generated the Receiver Operating Characteristic (ROC) curve. This curve illustrates the True Positive Rate (TPR – representing the proportion of accurately identified malicious SQLi requests) in relation to the False Positive Rate (FPR – denoting the percentage of legitimate requests incorrectly labeled as malicious) by iterating through all potential classification threshold values.
ModSecurity against the test set. The outcomes from our initial assessment are represented by the solid blue lines in Figure 3. The ROC curve for PL1 (the default PL setting for ModSecurity) underscores its limited effectiveness in differentiating between genuine and malicious SQL queries, as evidenced by a TPR of less than 50% for FPR values also below 50%. Among all the PLs, PL2 stands out as the most proficient, boasting a detection rate of 69.55% when the FPR is set at 1%. The ROC curves for PL3 and PL4, on the other hand, are nearly indistinguishable. This suggests that the additional two SQLi rules in PL4 don't enhance its detection efficacy.

ModSecurity against the adversarial test set.
The data from the adversarial test set paints a concerning picture, starkly revealing ModSecurity's vulnerability to adversarial attacks. As indicated by the blue dashed lines in Figure 3, regardless of the Protection Level (PL) in focus, the True Positive Rate (TPR) falls to 55.55% at a 1% False Positive Rate (FPR) - a performance just marginally better than mere chance. Though these observations are consistent with the guidance from the OWASP Foundation, which notes that higher PLs often result in increased false positives, it's evident that ModSecurity with CRS struggles to effectively safeguard applications and networks. This is true not just against known threats but also when faced with adversarial samples.
We then assessed the detection prowess of MLModSec using the SVM and RF methodologies. Both were calibrated using the CRS rules, as visualized in Figure 3. Their performance was gauged against two distinct datasets: the regular test set (test) and its adversarial counterpart (test-adv).
MLModSec: supercharge your ModSecurity.
The figure showcases the ROC curves, marked by continuous red and green lines. When juxtaposed with the baseline ModSecurity, the advantage of leveraging machine learning becomes evident, particularly in improving the True Positive Rate (TPR) for Protection Levels (PLs) above 1. Delving into the specifics from Table 1, the linear SVM's TPR, at a 1% False Positive Rate (FPR), eclipses that of ModSecurity by 18.65%.
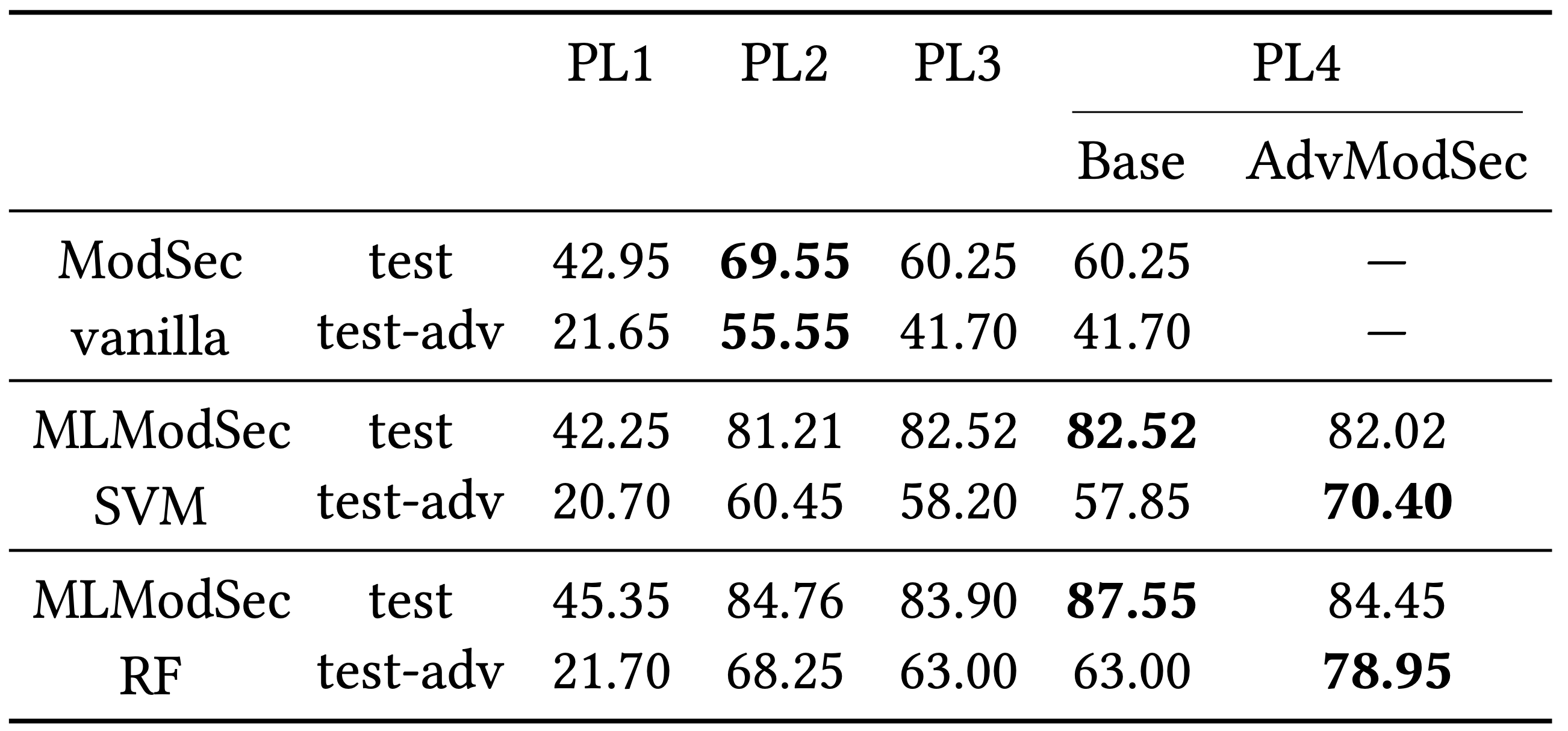
The RF model showcases a similar trend, outstripping ModSecurity's TPR by 25.8% at the same FPR. Interestingly, at PL1, both the machine learning models and the baseline ModSecurity produce almost identical results, hinting that the PL1 rules might not be the most effective in differentiating between benign and malicious inputs. Another notable observation is that the machine learning models register their peak detection rates at PL4, although the rates are just slightly superior to PL2. This indicates the machine learning models' capability to judiciously assign significance to each rule, achieving a harmonious balance between TPR and FPR, even when certain rules could elevate the false positive counts.
MLModSec Performance against Adversarial Inputs
On the resilience front, though the machine learning models are somewhat susceptible to adversarial incursions (as depicted by the interrupted lines in Figure 3), their performance still trumps the baseline ModSecurity. To be more precise, as per Table 1, against the adversarial dataset, the TPR at 1% FPR for the MLModSec linear SVM and RF models surpasses ModSecurity by 8.8% and 22.8%, respectively. A stark contrast emerges when compared to the benign environment, with PL2 emerging as the most effective PL in the face of adversarial threats. This highlights the ability of adversarial SQL injections to manipulate the rules of PL3 and PL4, evading detection by eliminating patterns that were considered pivotal during the training phase.
AdvModSec: ensuring robustness against adversarial attacks.
On the adversarial test set, AdvModSec demonstrates superior performance compared to its non-enhanced versions, showcasing greater resilience (as indicated by the dashed lines in Figure 4). To be specific, at a set threshold of 1% FPR, the linear AdvModSec SVM boosts its performance by 21.7% over the non-enhanced version, while the AdvModSec RF does so by 25.3%.

It's also noteworthy that the top-performing AdvModSec (RF at PL4) exhibits a robustness that's 42% greater than the best-performing standard ModSecurity (PL2). While AdvModSec isn't impervious to new adversarial samples tailored against it, the drop in its performance is less pronounced than what's observed in non-enhanced models.
Final remarks
In this post, we analyzed a recent research work that analyses the performances of ModSecurity and of the OWASP CRS and its resilience against adversarial attacks aimed to evade them. The key outcomes of the research work are:
The standard assignment of the severity levels to the detection rules assigned by domain experts remains a purely heuristic process that doesn't lead to an optimal tradeoff between the TRUE POSITIVE and the FALSE POSITIVE rates;
Optimization of the severity levels driven by an ML algorithm can lead to an improvement of up to 25.8% of the TRUE POSITIVES at the same FALSE POSITIVE RATE;
That ModSecurity and the CRS can be easily evaded with simple manipulations of the attack queries. And that here, adding a layer of robust machine learning trained to be resilient against adversarial attacks can lead to a robustness that's 42% greater than the best-performing standard ModSecurity.
References
Adversarial ModSecurity: Countering Adversarial SQL Injections with Robust Machine Learning - https://arxiv.org/abs/2308.04964
OWASP Top 10 - https://owasp.org/www-project-top-ten/
OWASP ModSecurity Core Rule Set - https://coreruleset.org
OWASP Coraza - https://coraza.io
WAF-A-MoLe - https://github.com/AvalZ/WAF-A-MoLE